Dans mon appli de documents, je voulais accentuer le document survolé dans la liste et diminuer les autres li. Ben ça se fait en ... un sélecteur CSS !
Je n'ai pas forcément compris toutes les explications mais l'article est vraiment intéressant.
J'imagine qu'il me faudrait réfléchir pour remplacer mon usage des media queries façon patch à la pelle de chantier des trucs qui foirent quand on change la taille du viewport... si je pouvais me passer des breakpoints...
Mais bon, j'ai déjà bossé à un refacto du css de mon appli de documents/exercices pour les élèves en modernisant le code à coups de nesting et de variables pour les couleurs... résultat, certains navigateurs au collège affichent de la merde parce qu'ils ne sont pas mis à jour
Je ne sais pas pour vous amis codeurs, mais de mon côté, si je n'ai pas un problème concret pour intégrer des nouveautés,impossible de les comprendre vraiment...
Je me note quelques astuces intéressantes. Toutefois, une remarque en passant... ARRÊTEZ DE FAIRE DES VIDÉOS DE PROGRAMMATION... à quoi ça rime ? on ne peut pas faire de copier coller, pas de récup auto de snippets, pas de tests... à part faire grimper votre popularité sur les raizosocio... pfff.
Oui, je sais qu'en description il a mis les snippets : mais il pouvait les inclures dans une page de blog, non ? Ou alors plus personne ne sait lire à part moi et on ne m'a rien dit ?!
un effet glow ou une ombre qui suit le background de la div.
L'astuce consiste à utiliser des pseudo éléments héritant du background de la div et à les blur.
Faire en sorte que la répartition du texte sur plusieurs lignes soit meilleure
En gros, le navigateur essaie de couper le texte de façon plus homogène
// pour les titres (peu de lignes)
h1{ text-wrap: balance;}
// pour les paragraphes etc (beaucoup de lignes): pas d'orphelin sur la dernière ligne
p{text-wrap:pretty;}
Pour toute personne voulant faire des plugins pour pluXML, j'ai mis à jour mon générateur de plugin: pour rappel, il sert à créer tous les fichiers et sous-dossiers préconfigurés selon vos choix.
J'ai mis à jour les hooks,
j'ai ajouté la gestion du scope (admin/site)
j'ai ajouté la possibilité de traduire les textes du frontend
j'ai changé un détail assez chiant: il ne plaçait pas les fichiers du zip dans le dossier du plugin...
J'ai amélioré la lisibilité du code... (un peu)
Je ne m'étends pas plus, vu que je dois être le seul à utiliser ça, mais bon.
Si toi aussi t'en as marre que le bouton Aperçu de la page article t'ouvre à chaque fois un nouvel onglet aboutissant rapidement à une accumulation visuellement insupportable du nombre d'échecs qu'il te faut avant de parvenir à un billet un tant soit peu abouti ? Alors ce ... «plugin» est pour toi: il se contente de changer le «_blank» de l'attribut onclick du bouton en «article_preview»... et ça, tu vois, ça change tout...
Désormais, la visualisation de l'article se fera toujours dans le même onglet (ouvert lors de la première visualisation)
Un plugin dérivé d'un de mes anciens qui s'avérait obsolète avec la nouvelle maquette. Il permet d'afficher un menu visible uniquement quand l'admin est connecté. Ce menu regroupe plusieurs icônes:
un lien vers l'espace admin
un lien vers un tag particulier: je m'en sers pour accéder aux articles publiés pour lecture ultérieure sous le tag «riditleteur»
un lien vers la page commentaires avec un décompte des commentaires non lus
un bouton de déconnexion
Il affiche de plus un lien sur chaque article pour éditer directement ce dernier (pratique pour corriger ou mettre à jour un article)
Ces deux fonctions sont accessibles via deux hooks, «editArticleIcon» et «adminPanel», dont il faut placer l'appel dans les pages header.php et articles.php du thème
Une page de config permet de redéfinir les icônes et texte des boutons ainsi que le tag du raccourci.
Je viens de procéder à une mise à jour de pluXml plugin starter:
ajout des hooks des dernières versions de pluXML
ajout d'une fonction permettant de filter les hooks afin de les retrouver plus facilement
ajout d'icônes unicode sur les boutons de sélection des hooks (plus faciles à identifier
dans l'optique d'en finir avec github, j'ai changé le lien de github en lien de téléchargement direct de la version courante, comme j'avais fait avec googol.
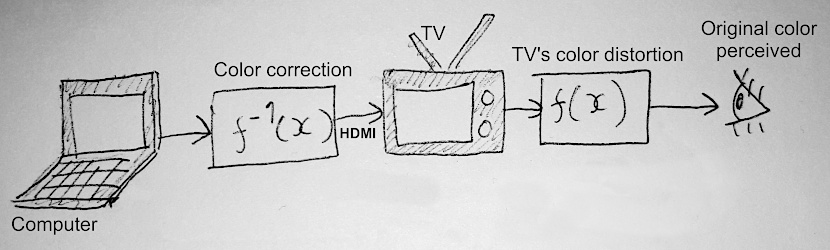
Superbe travail en effet: concevoir un shader pour compenser les irrégularités de luminosité d'une télé vieillissante.
Je suis fan du principe et pour une fois que le fait que les télés soient devenus des ordinateurs peut-être utile au lieu d'emmerdant...














 )
)









{kind=link}
{kind=link}
{kind=link}