CSS Compatibility Checker – Votre allié pour un code parfaitement compatible avec tous les navigateurs
sympa, on gagne du temps... ou alors il suffit de s'en foutre en mode ça marche sur mon ordi...











sympa, on gagne du temps... ou alors il suffit de s'en foutre en mode ça marche sur mon ordi...
Histoire de bosser un peu sur l'utilisation d'Imagick (pour lequel je m'étais fait des notes ici 12) j'ai essayé de faire une petite «api» de génération de badges simple.
On peut appeler l'api directement en précisant les variables suivantes:
?txt=trop beau|pas vraiapi.warriordudimanche.net/badgit/?txt=Mon%20super%20badge&backcolor=red&txtcolor=&icon=&font=montserrat.ttf&fontsize=16
api.warriordudimanche.net/badgit/?txt=Mon%20super|badge&backcolor=red|pink&txtcolor=pink|red&icon=&font=montserrat.ttf&fontsize=16
api.warriordudimanche.net/badgit/?txt=Mon%20super|badge|de%20ouf&backcolor=red|pink|maroon&txtcolor=pink|red&icon=&font=montserrat.ttf&fontsize=16
api.warriordudimanche.net/badgit/?txt=Mon%20super|badge%20|de%20ouf%20&backcolor=red|pink|maroon&txtcolor=pink|red&icon=|fontawesome_solid/smile-beam.svg|fontawesome_solid/hand-back-fist.svg&font=montserrat.ttf&fontsize=16

J'ai goupillé aussi un petit front basique, histoire de ne pas se taper tout au clavier.

Ça ne servira sans doute à personne mais bon, sait-on jamais 
Ceci dit, il y a une classe badge qui peut faire l'affaire quelque part...
Le code est là : https://api.warriordudimanche.net/badgit/?download


Depuis que mon grand est en fac d'info, on a un nouveau sujet de conversation et j'ai ENFIN un interlocuteur dans le domaine à la maison !
Du coup, il arrive le weekend avec les TP qu'il a eus pendant la semaine et me pose des questions sur les difficultés qu'il a.
En ce moment, il commence PHP et CSS/HTML...

Du coup, aujourd'hui, il travaillait sur la page de login pour le projet final, une todolist en PHP+HTML+CSS sans JS.
Il voulait faire des labels flottants parce qu'il avait vu que c'était joli... Comme il découvre le monde merveilleux du frontend, on s'y est mis à deux et on a improvisé un petit cours.
Il a appris les subtilités du ciblage, les pseudo éléments, l'usage de :not() et :has()...

Pour la page de démo: c'est par là.
Pour le code : c'est sur snippetvamp.
En gros, on veut que le label soit dans l'input, comme un placeholder, lorsque il est vide mais que le label reprenne une place normale lorsque l'utilisateur clique dans l'input pour le remplir.
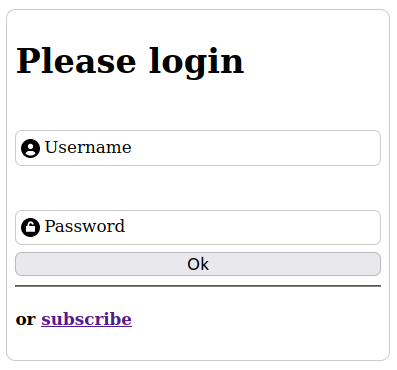
<label><span>Username</span>
<input type="text" name="login" value="" placeholder=" " >
</label>Ensuite, je déplace le span vers l'intérieur de l'input:
label span{
position: relative;
top:2em;
left:24px;
transition:all 500ms;/* et on fait une transition douce, merci*/
}Puis on utilise :has() pour cibler le span du label contenant un input ayant le focus.
label:has(input:focus) span
{
color:grey;
top:0;
left:0;
transition:all 500ms;
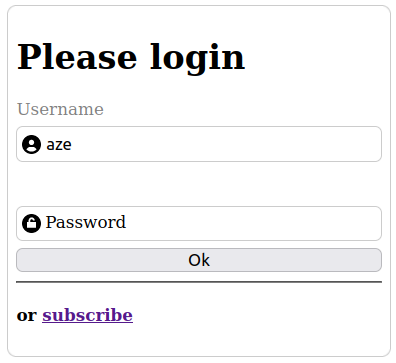
}À ce stade, quand l'utilisateur clique dans l'input, le label glisse vers le haut pour sortir de l'input.
Toutefois, le problème c'est que lorsque l'input perd le focus, le label revient à l'intérieur même si l'input a été complété... et les deux textes se chevauchent hideusement...

La logique voudrait qu'on cible alors le span du label contenant un input vide, genre avec input[value=""] ... sauf que ça ne marche pas car le fait de remplir un input ne modifie pas l'attribut value de la balise input...

Puisqu'on ne peut pas cibler un changement de l'attribut value, on peut cibler... le placeholder ! Enfin... styler en fonction de la visibilité du placeholder...
Ainsi, en utilisant :placeholder-shown, on peut ajouter une règle de ciblage au CSS précédent:
label:has(input:focus) span,
label:has(input:not(:placeholder-shown)) span
{
color:grey;
top:0;
left:0;
transition:all 500ms;
}Et là, les plus observateurs d'entre-vous - qui se demandaient avec une angoisse et un mépris non dissimulés pourquoi j'avais collé un placeholder=" " dans mon HTML - comprennent l'astuce: si le placeholder est visible, c'est que l'input est vide...
Et ça marche, tout est supporté dans la plupart des navigateurs. En plus, c'est léger, ne demande pas une structure HTML alambiquée ou des règles CSS à la mords-moi le zboub...
Si ça peut servir, c'est cadeau
Je me note ici pour une prochaine fois parce que fetch n'est pas forcément très intuitif...
fetch("index.php", { method: 'POST', body: formData })
.then((response)=>{
// on attend l'arrivée de la réponse et on la traite
return response.text(); // ou response.json();
})
.then((text)=>{
// on attend la fin du traitement de la réponse et on en traite le contenu
console.log(text);
});En gros, on crée une fonction asynchrone pour pouvoir utiliser les await.
const fetchAPI = async(URL) => {
const response = await fetch(URL); // on attend l'arrivée de la réponse
const data = await response.json(); // on attend la fin du traitement de la réponse
console.log(data)
}
fetchAPI("https://jsonplaceholder.typicode.com/todos/1")En ce moment je bosse sur l'appli de documents/exercices que j'utilise en cours (cf https://warriordudimanche.net/article1686/lappli-documents-que-jai-codee-pour-taf pour mémoire).
J'implémente toute une nouvelle rubrique et de nouveaux items afin de couvrir le spectre de l'expression orale de façon simple en ajoutant une sorte de labo de langue simplifié.En gros, je veux que le gamin puisse travailler à l'écoute de mots modèles mais également qu'il puisse s'enregistrer et se réécouter simplement et quelque soit le support...

Les frontend qui me lisent voient de suite où ça va couiller (merci les copaines)
Et oui, j'ai codé un truc qui fonctionne très bien, relativement propre et simple, facile à utiliser... sous Firefox, opera, vivaldi, chromium et sous Android.
Hélas, ma solution utilise l'API MediaRecorder qui semble présenter des difficultés sous certains navigateurs, vous devinez lesquels...
J'ai testé sur safari (enfin epiphany passque j'ai pas d'apple sous la pogne, tu te doutes...) et ça refuse de fonctionner, vu que MediaRecorder y est bloqué pour nôôôtre saicuritay...
J'ai ensuite testé sur Edge avec mon portable et ça n'a pas fonctionné... toutefois, quand j'ai installé le deb d'Edge sur mon linux ⬇⬇⬇ ...

...là, ça a fonctionné... Mais si ça marche, ça doit venir de Linux et pas de Edge (mauvaise foi inside )
Donc en gros, on revient à des soucis de compatibilité avec le nouvel IE ?! (ouelcome to aoueur fanne tasse tique taïme meuchine !)

Pourtant, canIuse me dit que ça devrait fonctionner, même sous Safari:

Bon, avec le navigateur à la pomme, il y a bien une manip à faire dans la configuration avancée pour les devs qui pourrait débloquer la situation mais je me vois mal demander ça à des élèves qui éprouvent déjà des difficultés non négligeables à discerner la barre d'adresse ou qui peinent - la sueur au front - à taper une majuscule sans passer par la touche de verrouillage...


Donc, là, pour le moment, rien à faire dans l'immédiat pour utiliser simplement MediaRecorder avec safari ou Edge... j'ai donc opté pour une «solution» temporaire: en cas d'absence de l'API, j'ajoute une classe spécifique et je disable les recorders de la page, puis j'affiche un message d'avertissement avec des liens vers des navigateurs compatibles (firefox et forks en tête)...
Après, j'ai bien trouvé un polyfill qui pourrait faire le job ( https://github.com/ai/audio-recorder-polyfill ) mais je ne l'ai pas testé, c'est un peu lourd à installer et pis... c'est pas moi qui l'ai fait... 
Allez, pour une fois, j'ai un peu de temps devant moi, je vais éplucher un peu la lib Image magick dont je parlais il n'y a guère...
Simple: pas besoin de plusieurs fonctions selon le format, il suffit de $images = new Imagick('image.jpg');
Même pas nécessaire de passer par un foreach, on fournit le tableau des fichiers voire directement un glob: $images = new Imagick(glob('images/*.JPG'));
$im->writeImage('image.jpg');
Si on laisse une dimension à 0, les proportions sont conservées (quand tu vois la merde que c'est avec GD !)
$image->thumbnailImage(100, 0);
header('Content-type: image/jpeg');
$image = new Imagick('image.jpg');
# ici on effectue un traitement puis on sort le résultat
echo $image;$im->getImageWidth() $im->getImageHeight()$im->getImageFormat() $im->setImageFormat('png'); ! 😍$im->NewImage(largeur,hauteur,couleur de fond);
Comme pour GD, il faut créer un objet couleur dans les traitements d'image, mais c'est plus simple qu'avec GD (et plus complet): il suffit de passer une couleur selon les normes CSS. Du coup, la transparence n'est pas gérée par une connerie de paramètre «alpha» mais simplement par ... rgba()... 💖
$couleur=new ImagickPixel("white");
$couleur=new ImagickPixel("#FFF");
$couleur=new ImagickPixel('rgb(255,255,200)');
$couleur=new ImagickPixel('rgba(255,255,200,0.5)');🆒 ⮕ Ça peut paraître compliqué, mais en fait, dans les fonctions où on est sensé utiliser ImagickPixel, je me suis aperçu qu'on pouvait tout simplement passer une string contenant la couleur css... elles se démerdent seules. 😍
$im->borderImage(new ImagickPixel("white"), 5, 5);$im->setFont("example.ttf");$im->negateImage(0);$im->normalizeImage();$im->autoLevelImage();$im->gammaImage(5);$im->contrastImage(niveau)$im->brightnessContrastImage(niveau luminosite, niveau contraste);$im->equalizeImage()$im->colorizeImage("red",0.5); 🤬 pas réussi à l'utiliser pour ce test...$i->resizeImage(250,0,Imagick::FILTER_POINT,0);$im->cropImage(200,200,50,50);$im->flipImage() pour retourner horizontalement$im->flopImage() pour retourner verticalement$im->rotateImage(new ImagickPixel('#00000000'), 75);$im->->setImageOpacity(0.3); $im->blurImage(5,2);$im->gaussianBlurImage(5,2); $im->motionBlurImage(5,5,45);$im->posterizeImage(5,0);`$im->addNoiseImage(imagick::NOISE_GAUSSIAN ); voir les constantes de type de bruit $im->sketchImage(rayon, deviation, angle);$im ->charcoalImage(rayon, deviation);$im->->shadeImage(1, 90, 2); # emboss + image grisée$im->shadeImage(0, 90,2) # emboss sur l'image d'origine (couleur)$im->oilPaintImage(5);$im->edgeImage(5);$im->waveImage( 10, 10);$imageclonee=$image->clone();$im->compositeImage($autreimage, imagick::COMPOSITE_OVER, 0, 0); (la composition, la façon de mélanger les images, peut être une de celles-ci https://www.php.net/manual/fr/imagick.constants.php#imagick.constants.compositeop)Image Magick me semble particulièrement bien nommée tant les possibilités sont énormes et la simplicité d'utilisation étonnante: on sent une volonté de se simplifier la vie lors de l'utilisation... c'est juste beau.
Je voulais mettre une image de chaque effet dans les descriptions mais:
 : http://test.warriordudimanche.net/imagick/
: http://test.warriordudimanche.net/imagick/ Tout le monde connaît les licences libres habituelles mais il y en a de moins connues et - souvent - moins compliquées à comprendre : petit florilège...

Permet de distribuer avec le même niveau de protection que le domaine public, c'est-à-dire AUCUN.

Faites ce que vous voulez et si un jour on se rencontre et que vous trouvez que mon boulot en vaut la peine, payez-moi une bière.

La réponse à toute question à propos des droits de reproduction ou problème légal est : «Sure, No problem. Don't worry, be happy. Now bugger off»

En gros, faites ce que vous voulez et ne me contactez pas.

Démerde-toi, demande pas d'aide et - surtout - ne dis à personne que ça vient de moi...

«Toute personne qu'on prendra à distribuer ce livre sans permission se verra considéré comme un super pote parce qu'on en a rien à foutre...»

Littéralement, la Licence Démerdez-vous... Je vous laisse la lire tranquilou pour vous faire une idée: toute tentative de résumé serait une trahison du texte original
«Cette Licence» se réfère à la version 1 de la «Demerden Sie Sich License» (le texte original en français). «Démerder», se réfère au sens de se «débrouiller». A aucun moment «cette Licence» ne vous demandera de vous enduire (vous ou votre œuvre) d'excréments humains (ni même animal). «Œuvre» est aussi appelée «travail» (quelques fois, l'extension «de sagouin» peut lui être apposée), «programme» ou tout autre terme relatif à ce qui a été effectué. Ainsi, une «documentation» ou un «manuel» peut être considéré comme une œuvre. «Auteur» signifie que la personne (ou groupe de personnes), qui utilise «cette Licence», se lave complètement les mains de la façon dont vous utiliserez son œuvre.
L'«Auteur» peut-être considéré comme irresponsable et il incombe à l'utilisateur en priorité de se «démerder» par lui même.

This software may not be used directly by any living being.
En gros, l'usage à toute personne vivante est formellement interdit.

Conditions très exotiques pour cette licence qui régule drastiquement la redistribution des copies du code:

- You do not talk about the FIGHT CLUB LICENSE.
- You DO NOT talk about the FIGHT CLUB LICENSE.
- If someone says "stop" or goes limp — or taps out — the project is over.
- Only two developers to a project.
- One project at a time.
- No shirts, no shoes.
- Projects will go on as long as they have to.
- If this is your first time reading the FIGHT CLUB LICENSE, you HAVE to license your next project under the FIGHT CLUB LICENSE.

L'auteur de toute modification doit redistribuer le travail modifié par un moyen plus contraignant et difficile que celui par lequel il a acquis le code original.

Heu, là, je vous laisse aller la voir tous seuls.... passque bobo têtête.

Pour faire court, c'est pas un bug c'est une fonctionnalité...
- Bugs in the licensed work are features, to be cherished, documented, and developed upon.
- Modified works must not include known bugs.
- Where identified, modified works' bugs shall be fixed.
- Authors and maintainers of the licensed work reserve the right to pull bug fixes from modified or derivative works without compensation, recognition, or any other reference to the authors of the bug fix.

Je crois que c'est clair...

Tu veux redistribuer ?! signe ici... avec ton sang.

Seule restriction : il est définitivement et formellement interdit de refactorer ce logiciel en Python 2.

Une licence qui autorise tout avec pour seule condition de ne pas être un connard (a dick)... l'auteur fournit une liste non exhaustive de ce qu'il appelle être un connard:

Vous voulez partager un logiciel ou un code en interdisant toute exploitation commerciale capitaliste et libérale ? Cette licence permet de restreindre l'usage et l'exploitation à certains types d'utilisateurs:

L'utilisateur a le droit... de demander la permission et l'auteur a l'obligation d'accepter
)
J'ai eu envie de faire ça car j'en avais assez de passer par le combo
Du coup, il suffit d'ajouter l'adresse de l'api à l'url vers la ressource distante...
Donc http://insta.com/image.jpg devient par exemple http://api.warriordudimanche.net/fetchit?url=http://insta.com/image.jpg
Fetchit va récupérer la ressource en local et vous servir cette version au lieu de la distante. Comme d'hab' si cette ressource a déjà été récupérée elle n'est pas re téléchargée.
Le deuxième effet kiskool (paye ta réf de vieux) c'est que du coup, comme getlib, ça permet de récupérer toute lib en local et être plus RGPD friendly.
Afin d'éviter que votre server ne se retrouve floodé par des fichiers vidéos 8K à 60 gigots l'unité, il y a une limite de taille configurée dans la constante SIZE_LIMIT, fixée par défaut à 10 Mo.


Comme d'hab', c'est cadeau... Utilisez, partagez, modifiez... juste respectez la Dont be a dick licence
Comme tout ça n'a de sens que si on héberge soi-même, vous pouvez récup' le zip qui va bien ici : https://api.warriordudimanche.net/fetchit/?download
Mes chers cons-patriotes, non aux fuites de données, vive le oueb libre et participatif et vive la france et bisou !
https://antoineboursin.fr/courses/creez-un-editeur-de-texte-wysiwyg
La vie est mal faite: je découvre document.execCommand() permettant de faire du richtext dans un élément contentEditable juste quand il est officiellement déclaré obsolète...
Bon, en même temps, sur stackoverflow, the holy baïbol, certains affirment que:

Petit bout de code fait à la va-vite dans le but de vérifier la validité des liens d'une page. Mon objectif est de pouvoir à terme montrer automatiquement les liens ne répondant plus sur la page où je regroupe les liens de téléchargement illégal
Dans le code ci-dessous, j'utilise fetch et les promesses pour lancer des requêtes afin de styler les liens testés:
function checkLinks(nodelist){
function checkUrl(link){
return fetch(link).then(function(response){
return response.status;
}).catch(function(error){
return error.status;
});
}
if (!nodelist){
checkLinks(document.querySelectorAll('.checkLink'));
return;
}
for (let obj of nodelist){
if (obj.tagName=="A"){
checkUrl(obj.href).then(function(response){obj.classList.add("status"+response);});
}else if (obj.hasAttribute("src")){
checkUrl(obj.src).then(function(response){obj.classList.add("status"+response);});
}else{
checkLinks(obj.querySelectorAll("*[href],*[src]"));
}
}
}
checkLinks();J'ai d'abord fait une fonction qui appelle une URL et renvoie une promesse qui, une fois résolue, renverra le statut de la requête. On y retrouve .then qui renvoie le statut d'une requête qui aboutit et .catch qui renvoie celui d'une requête se soldant par une erreur.
function checkUrl(link){
return fetch(link).then(function(response){
return response.status;
}).catch(function(error){
return error.status;
});
}Les plus coquinous d'entre-vous me feront remarquer à juste titre que, vu ce que je renvoie, je pouvais me contenter de
function checkUrl(link){
return fetch(link).then(function(response){
return response.status;
});
}Ceci dit, en prévoyant les deux cas, je m'autorise à gérer le retour différemment selon si ça aboutit ou pas (par exemple retourner «ok200» ou «error404»
Ce block n'est là que pour simplifier la vie de l'utilisateur en lui évitant de procéder lui-même au querySelectorAll()
if (!nodelist){
checkLinks(document.querySelectorAll('.checkLink'));
return;
}Je parcours la nodeList en vérifiant l'URL passée en href (pour les A) ou en src (pour les img par exemple).
Le dernier cas est celui où l'on souhaite vérifier les liens contenus dans un div portant la classe .checkLink : il suffit d'appeler la même fonction de façon récursive en lui fournissant le nodeList des liens contenus das le DIV en question. (ça permet de vérifier un grand nombre de liens sans avoir à leur ajouter individuellement la classe .checkLink, ce qui est particulièrement utile quand on publie des articles en utilisant markdown )
for (let obj of nodelist){
if (obj.tagName=="A"){
checkUrl(obj.href).then(function(response){obj.classList.add("status"+response);});
}else if (obj.hasAttribute("src")){
checkUrl(obj.src).then(function(response){obj.classList.add("status"+response);});
}else{
checkLinks(obj.querySelectorAll("a,img"));
}
}Il suffit de mettre la classe .checkLink à tout objet dont on veut tester les liens et de coller la fonction dans la page puis de l'appeler via un checkLinks(); de bon aloi.
En l'état, la fonction ajoutera une classe .status200 pour les liens ok ou .status404 pour les URL qui ne répondent plus.
Il ne reste plus qu'à styler ces classes en changeant la couleur, le fond ou en ajoutant des emoji avec un petit content. On peut même éventuellement masquer un objet dont l'URL ne répond pas...
Le script étant en JS, il se heurte évidemment aux règles de la politique CORS: toute requête hors du domaine en cours va échouer à moins de redéfinir le CORS dans le Head de la page via
<meta http-equiv="Content-Security-Policy" content="Content-Security-Policy:..."/>
Comme d'habitude, il s'agit autant d'un proof of concept que d'une truc utile... en tout cas, n'hésitez pas à en faire rigoureusement ce que vous voulez: c'est cadeau...
Parfois, un post en entraîne un autre... Ainsi, tu t'es mis à coder un BOT presque par inadvertance - avec les difficultés qu'on connaît - et tu le partages parce qu'il n'y a pas de raison que l'auteur soit le seul à pleurer... pis t'as un copain qui te lit et qui prend le truc au sérieux... en tout cas suffisamment pour te proposer d'en faire un autre !

Objectif de la demande: récupérer les données de l'API RTE tempo ( https://data.rte-france.com/catalog/-/api/consumption/Tempo-Like-Supply-Contract/v1.1 ) pour dire la couleur du jour et celle du lendemain et les poster sur un bot mastodon (mais pouvoir appeler le script comme une API aussi)
Je suis donc parti pour tester ladite API: pour la faire courte, ça m'a permis - après les galères d'usage - de comprendre comment tout ça fonctionnait (en particulier la demande d'un token, l'appel d'une api en php etc)
J'en suis arrivé à un script qui produit un texte donnant la couleur du jour et celle du lendemain.
Le texte c'est bien, mais ce serait mieux si on pouvait récup les données en HTML et intégrer ça avec une Iframe, comme un code d'intégration.
Pis éventuellement en RSS aussi...
Bon, tant que j'y étais, j'ai aussi fait un mode json, au cas où on voudrait ça dans un frontend à soi...
Du coup, mon API s'appelle de plusieurs façons différentes:
Le script produit un fichier pour chaque type de retour et ne le régénère qu'une fois par jour afin d'éviter de se faire «hammerer» comme dit @parigotmanchot
À ce stade, le script fonctionne même si le code est un peu sale et pas bien rangé... il fait ce qu'on lui demande. A part que parfois, il ne donne pas la couleur du lendemain... mais pas en local... juste en distant. Je n'ai pas encore vraiment cherché pourquoi, mais je pense que c'est dû au moment où l'on appelle l'API de RTE.
Tant que j'y étais, j'ai regardé l'API ECOWATT ( https://data.rte-france.com/catalog/-/api/consumption/Ecowatt/v4.0 ) qui donne une couleur et un message décrivant le niveau de stress du réseau.
Du coup, le script appelle les deux API et retourne les données cumulées des deux.


Si ça vous intéresse, le zip est là : RTETempo.zip et il est distribué sous stricte licence faites-en ce que vous voulez. 😅
Les constantes au début permettent de configurer un peu:
TOKEN_BASE64 : pour mettre votre propre jeton si vous voulez vous inscrire sur RTE (qui accepte les emails jetables type yopmail, je dis ça je dis rien 😬)TEMPO_BEFORE_TODAY, TEMPO_BEFORE_TOMORROW, ECOWATT_BEFORE_TODAY, ECOWATT_BEFORE_TOMORROW : pour définir le texte renvoyé avant la couleur.HTML_STYLE : pour changer le style du HTML généréTEMPO_HTML_TEMPLATE, ECOWATT_HTML_TEMPLATE : pour changer le code HTML à utiliser en cas de retour HTMLECOWATT, TEMPO : deux booléens permettant de débrayer l'un ou l'autre des appels (si vous ne voulez que ECOWATT ou que TEMPO)Ben j'ai fait un autre BOT pour poster les couleurs du réseau une fois par jour... https://piaille.fr/@RTE_color ( @RTE_color@piaille.fr )

Hier, je me suis aperçu que le bookmarklet que j'avais fait pour trouver le flux RSS d'une chaîne youtube ne fonctionnait pas toujours 🤬: en effet, si l'URL de la chaîne n'est pas du type www.youtube.com/channel/xxxCHANNEL_IDxxx ça ne fonctionne pas... Or, les chaînes peuvent être aussi sous une forme dans laquelle le channel_id n'apparaît pas.

Au lieu de laisser youtube me chier dans les bottes, je me suis dit que, si le channel_id n'est pas dans l'URL, il doit être planqué quelque part dans le html de la page.
En fouillant un peu, twingo bongo jannielongo bingo 🥳 J'ai trouvé ça en parsant avec (presque) la même regex que pour l'URL.

J'ai donc codé vite fait une «api» qui renvoie l'URL du flux RSS d'une chaîne Youtube dont on fournit l'adresse.
On peut l'utiliser avec le frontend minimaliste prévu, en faisant une requête GET ou via le bookmarklet qui va bien.
Le tout est bien entendu utilisable, autohébergeable et modifiable, comme d'habitude
Allez !



Si toi aussi t'en as marre que le bouton onclick du bouton en «article_preview»... et ça, tu vois, ça change tout...
Désormais, la visualisation de l'article se fera toujours dans le même onglet (ouvert lors de la première visualisation)
Un truc qui me chiffonnait dans la rédaction d'articles un peu longs, c'était:

Grâce à ce plugin, on ne passe plus son temps à défiler QUE dans la page 
En effet, il redimensionne les textareas de la page article en fonction de leur contenu. La zone de texte grandit avec le volume de texte tapé dedans.
Un plugin dérivé d'un de mes anciens qui s'avérait obsolète avec la nouvelle maquette. Il permet d'afficher un menu visible uniquement quand l'admin est connecté. Ce menu regroupe plusieurs icônes:

Il affiche de plus un lien sur chaque article pour éditer directement ce dernier (pratique pour corriger ou mettre à jour un article)
Ces deux fonctions sont accessibles via deux hooks, «editArticleIcon» et «adminPanel», dont il faut placer l'appel dans les pages header.php et articles.php du thème
Une page de config permet de redéfinir les icônes et texte des boutons ainsi que le tag du raccourci.

Si ça peut vous servir, c'est cadeau !

Bon, je ne vous cache pas que c’est long niveau processing et je ne pense pas que ce sera vraiment utilisable pour de l’application web grand public. Mais c’est rigolo.

Ça fait un moment que je parle de certaines de mes applis au fil de billets ou de commentaires, en particulier de celle que j'utilise au boulot. Un très long billet totalement dispensable destiné à ceux que l'enseignement intéresse (ou les logiciels dans l'enseignement)
Je me suis dit que ça pouvait intéresser des gens de voir avec quoi je taffe.

Tout est venu de l'aspect pour le moins instable et aléatoire des logiciels et environnements proposés dans le cadre de mon boulot que ce soit au niveau du ministère, de l'académie, du département ou même du collège.
En gros, on change soit de logiciel soit d'environnement soit de machines à peu près tous les ans ou les deux ans, ce qui induit une certaine appréhension au niveau de la conservation de nos données: les exercices réalisés dans les exerciseurs disparaissent, les données et documents de l'ENT également... bref: c'est du taf inutile à se retaper tous les ans (ou deux ans) 💩
Mon autre souci, c'est que les logiciels proposés sont rarement utilisés par ceux qui les codent puisqu'il s'agit d'applis à caractère administratif (appel/cahier de texte etc) ou pédagogiques (exerciseurs / stockage de données / expos etc)
Résultat, l'UI est merdique et il est impossible de faire la moindre opération sans un nombre de clics qui à lui seul justifierait qu'on vire le bureau d'études. Quand tu dois swapper clavier souris trois fois pour juste une case à cocher, on a un problème. 😬
Ce problème vient du fait qu'à vouloir donner la possibilité de réaliser des choses complexes, on complexifie inutilement la réalisation des choses simples... or, on fait plus souvent des cases à cocher ou des cases de texte à remplir que des formulaires insérés dans des vidéos. 😭
Pour ma part, j'attends d'une appli destinée aux élèves et aux professeurs que:
Pour les élèves:
Pour moi:
Il s'agit d'une appli en ligne de consultation libre des documents utilisés en cours.
Côté élève, un lien de partage conduit à la page que j'utilise en classe pour faire cours: il a donc toutes les ressources pour revoir la leçon ou récupérer le cours en un seul lien.
Cette même page me permet de mettre une image en plein écran en un clic, de faire plusieurs diapos simplement etc.
Côté enseignant, elle fournit un explorateur de fichiers , un éditeur de pages etc. On peut ainsi créer un nouveau dossier de travail pour les 5ème, y déposer en une fois mp3, images etc, y créer une page dans laquelle on organise le tout et même créer des exercices numériques sans que ça prenne plus de temps de le faire là que de le faire sous libreoffice (souvent, la version papier me prend grave plus de temps que la version numérique en fait 😅)
La racine de la page d'accueil donne accès à tous les niveaux

et dans chaque niveau, une page unique liste tous les documents disponibles. Quand le prof cherche le document du jour, il peut filtrer en tapant une partie du nom du dossier contenant lesdits documents.

Une fois sur le document, l'élève (ou le prof en classe) a une page claire avec documentation, questions, liens vers les fiches de révision et pdf éventuellement distribué.

L'enseignant peut également ajouter des éléments de formulaire dynamiques permettant de sélectionner, cocher, ordonner, compléter

J'ai ajouté un bouton servant à changer la police de caractères pour l'opendyslexic:

Le prof a un filemanager pour créer des dossiers et des fichiers simplement, uploader en glisser-déposer, éditer des fichiers. L'accent a été mis sur la rapidité et la simplicité d'utilisation.

Si on se contente d'uploader sans mettre de page, le lien générera une page complète avec les documents. Sinon, on ajoute une page html qu'on édite ensuite (deux clics)

Tous les fichiers constituant un «document de classe» se trouvent dans le même dossier par défaut: si on crée des sous-dossiers dans celui du document, chaque sous-dossier devient une diapo indépendante générée comme des pages individuelles. Lorsqu'on se rend sur la page de partage, on passera de l'une à l'autre avec les flèches du clavier ou celles apparaissant sur les côtés de l'écran... pas besoin de se faire chmir à créer les diapos, les lier que sais-je.
On a donc: ROOT> niveau> document> fichiers ou ROOT> niveau> document> diapo1>fichiers , ROOT> niveau> document> fichiers>diapo2>fichiers etc.
Pour la mise en page, on utilise markdown, donc, du texte brut. Hors de question pour moi de devoir me prendre le chou avec des mises en page compliquées.
Sur ce principe, pas de boîtes de dialogue, de clics multiples pour créer des exos: tout se fait par deux types de «balises» sans lâcher son clavier:
Propres à mon framework perso, je les ai adaptées à Documentos:
Les éléments de formulaire sont générés via des commandes gu genre {{app->flashcards("")}} qui ne sont pas super simple à mémoriser ou sexy à voir. Du coup, j'ai créé des aliases plus simples qui utilisent les crochets. Ainsi:
Le fait de ne jamais quitter le clavier supprime la plupart des clics et la perte de temps du passage entre clavier et souris. ça s'avère redoutable dès qu'on a un peu l'habitude: on ne s'occupe que du contenu sans jamais perdre de temps à chercher comment faire (friction d'utilisation minimale)

T'inquiète, mon con de chef m'a suffisamment fait chier avec ça pour que je ne coure aucun risque (faire une recherche sur ce site avec le mot clé «j'abandonne» 😡):
J'utilise Documentos depuis 2018 et je le modifie régulièrement. L'utilisation au quotidien est top et lors du confinement, je n'ai pas eu à changer grand-chose pour que le distanciel soit possible... je pouvais fournir presque en temps réel et mes élèves ont pu bosser dès les premières minutes de confinement sans être déroutés et depuis n'importe quel appareil (là où l'ENT était à genoux dès 8:10)
Je ne fournis pas le code de Documentos pour plusieurs raisons:
Après, on peut discuter, hein 😉